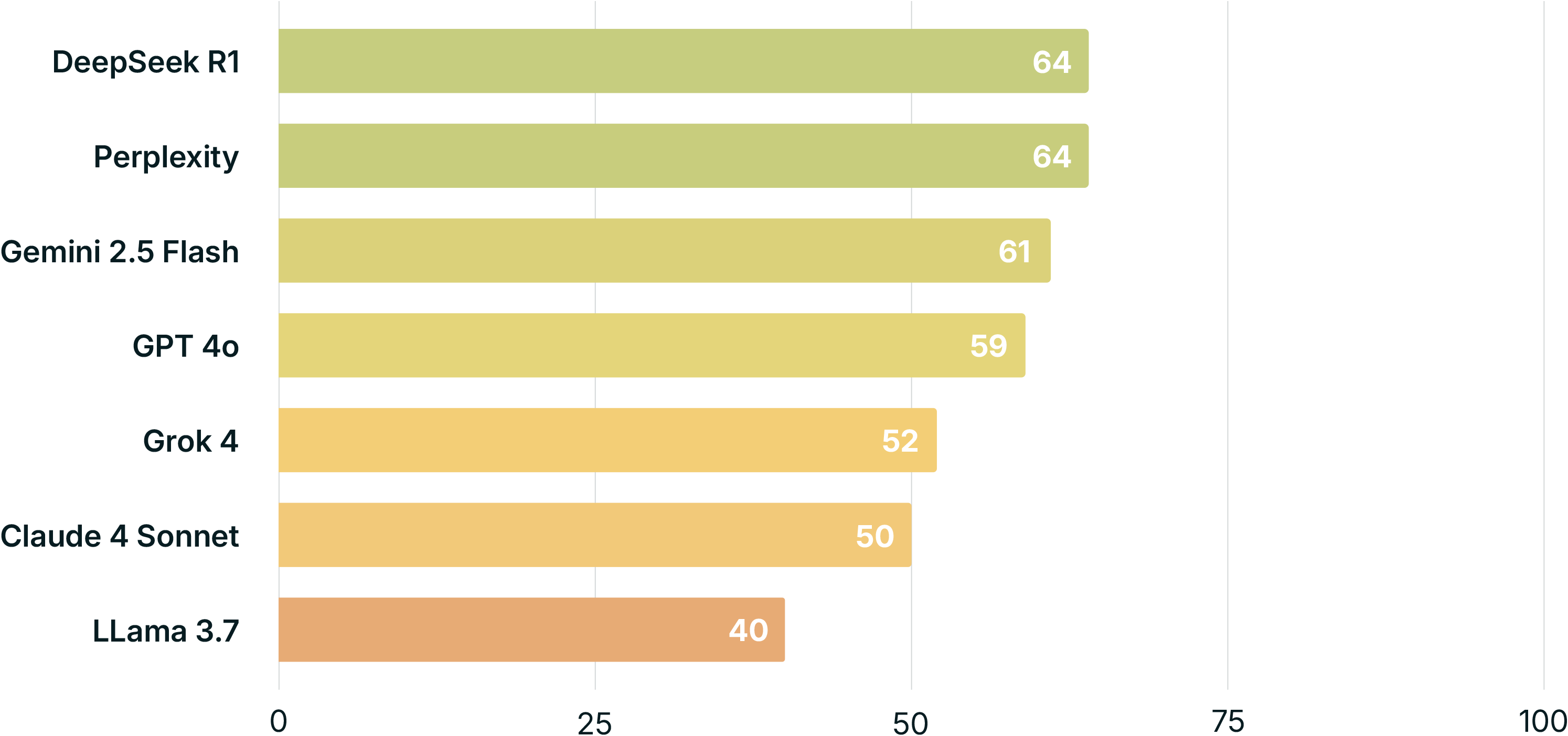
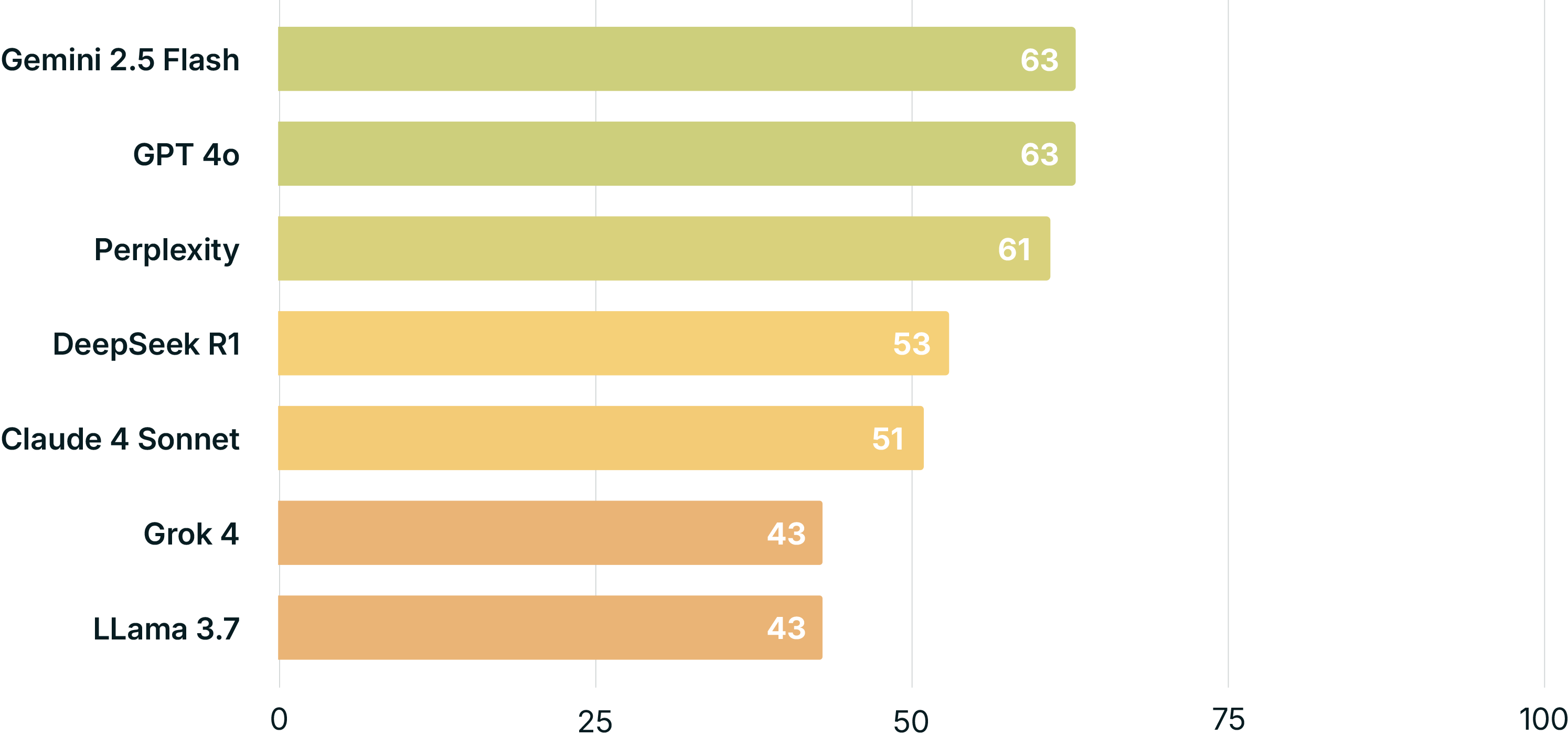
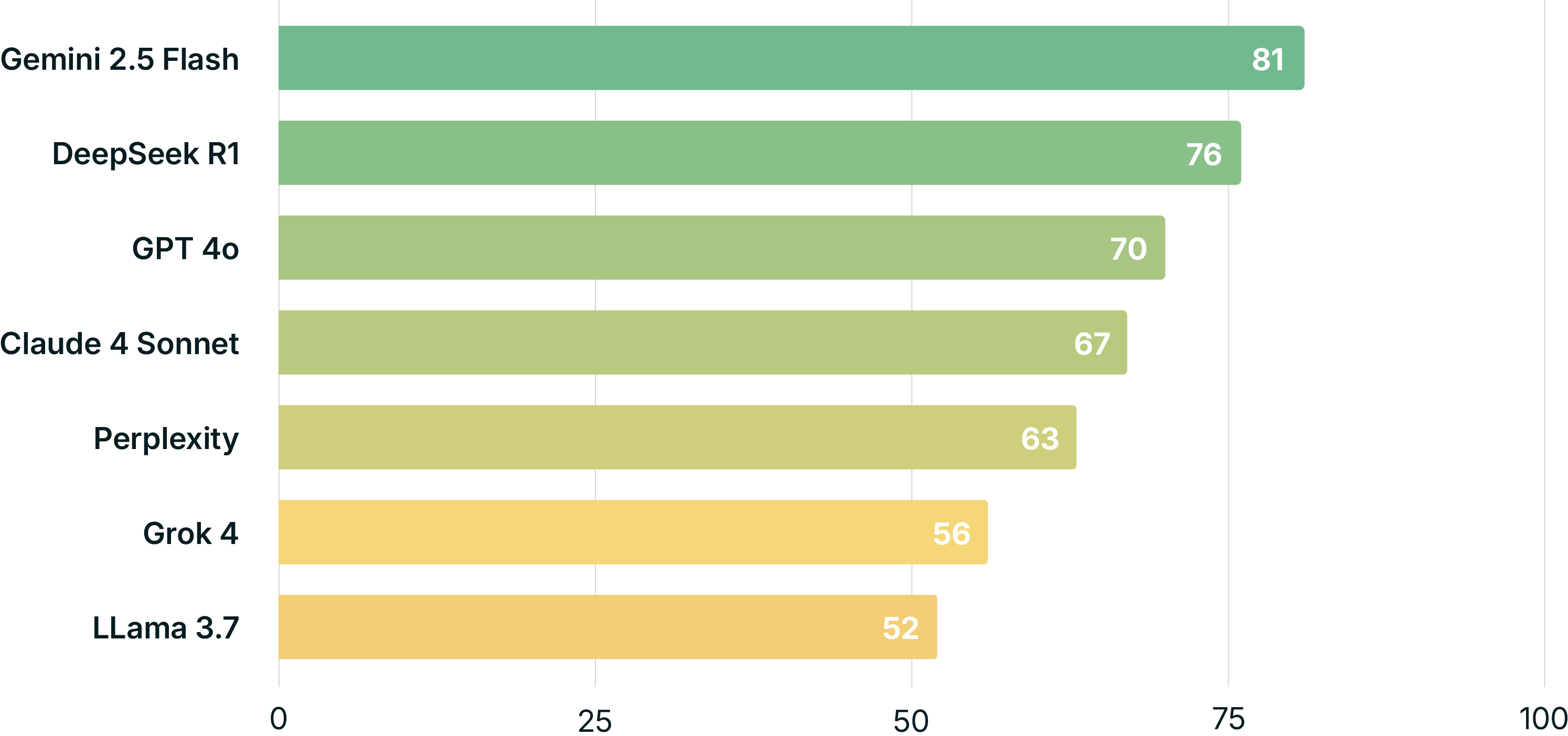
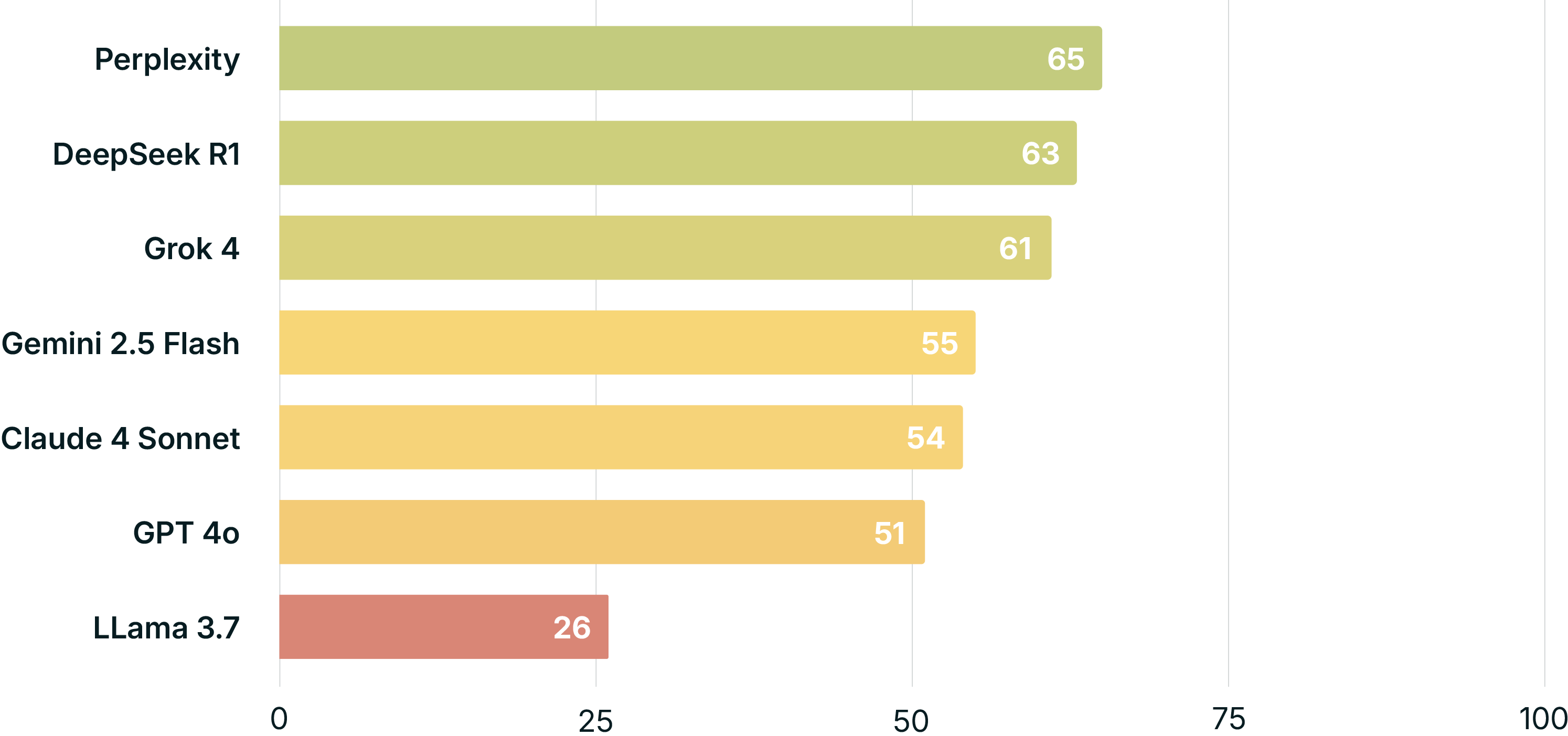
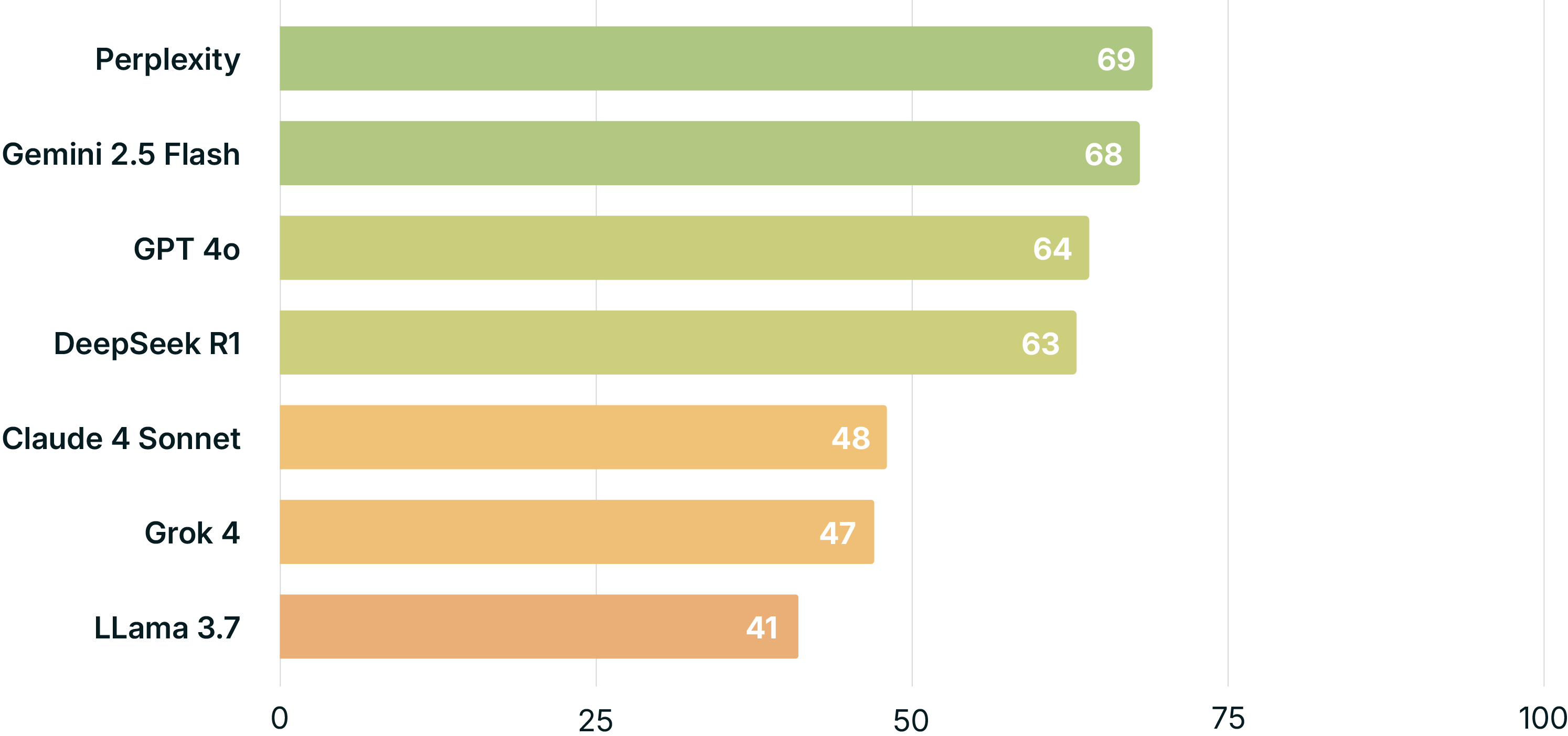
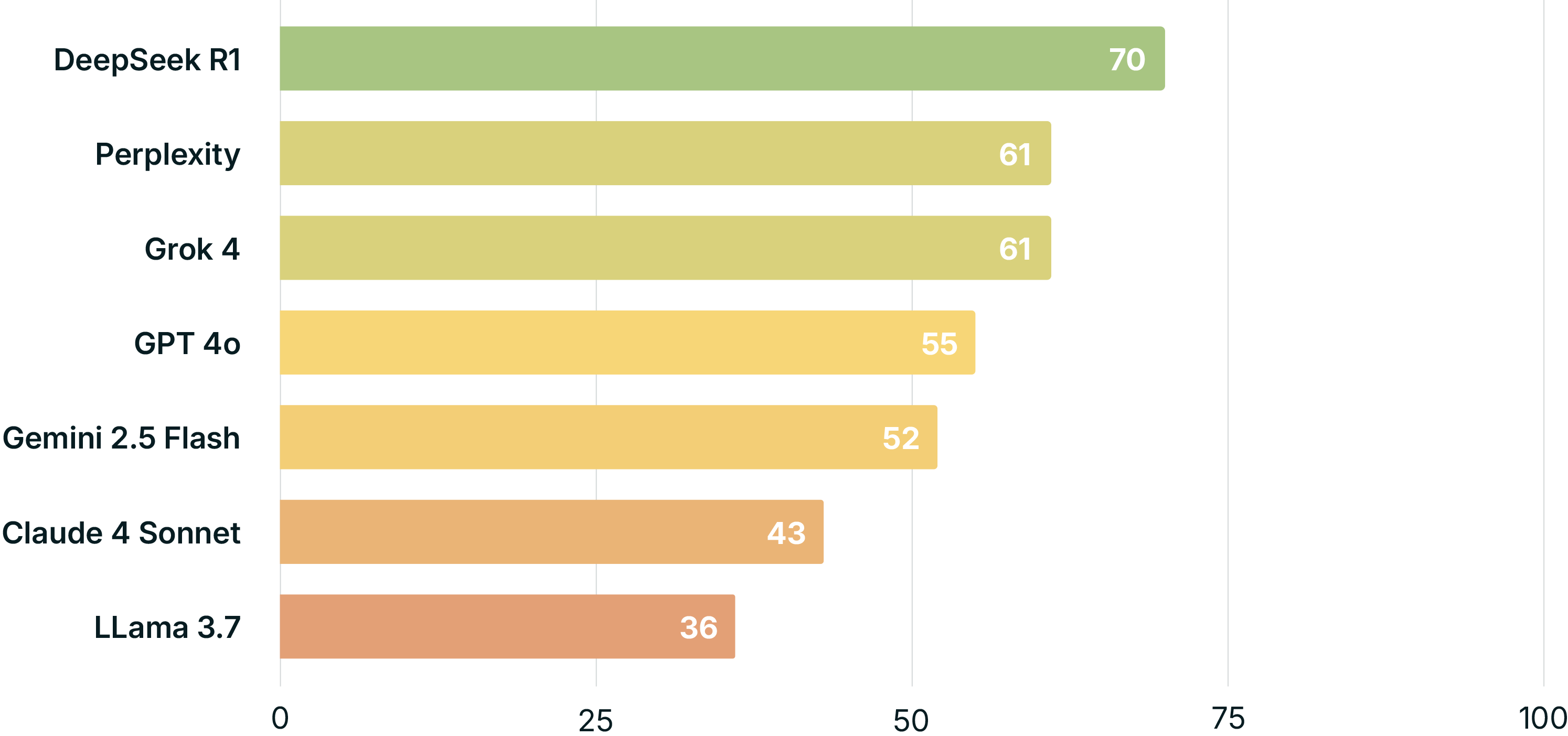
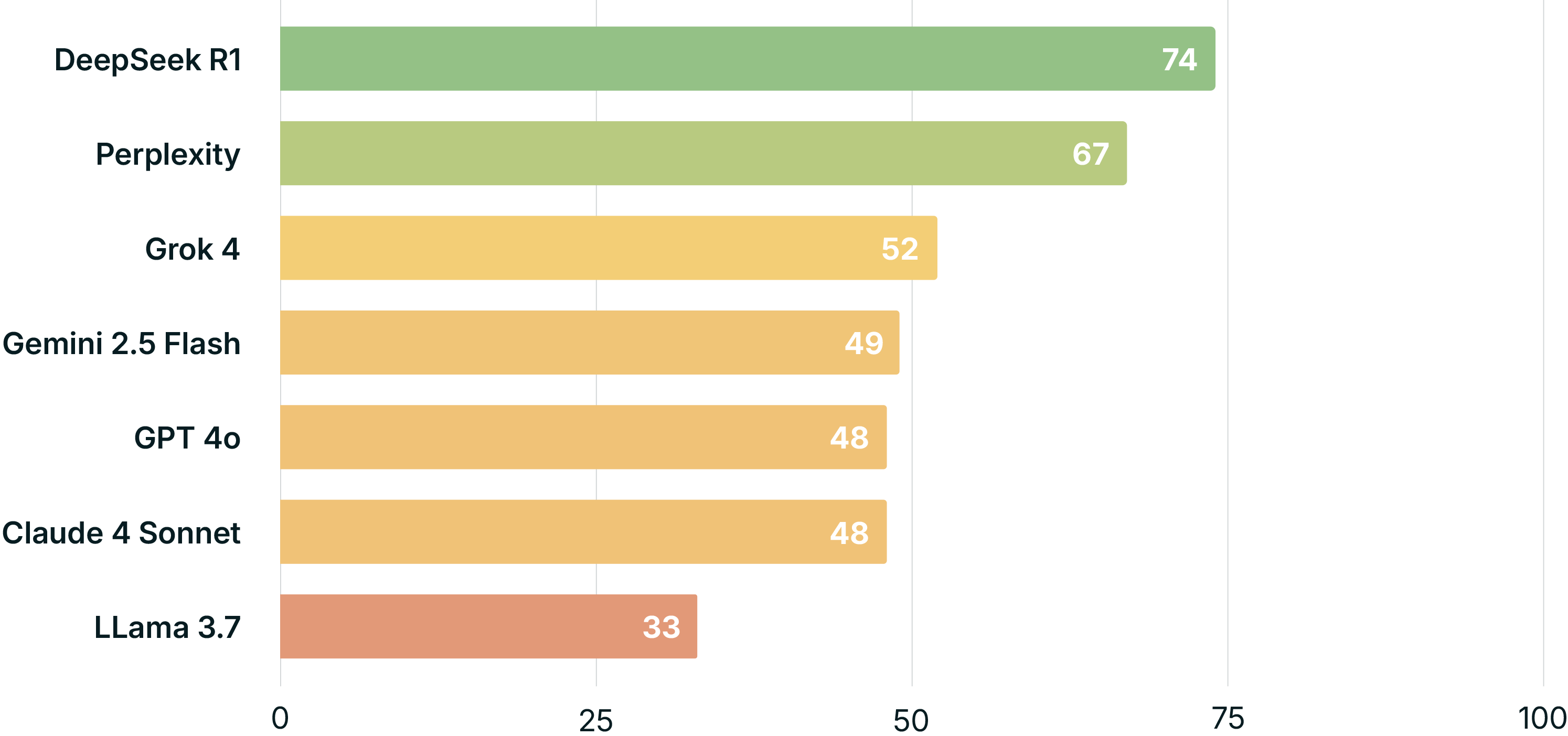
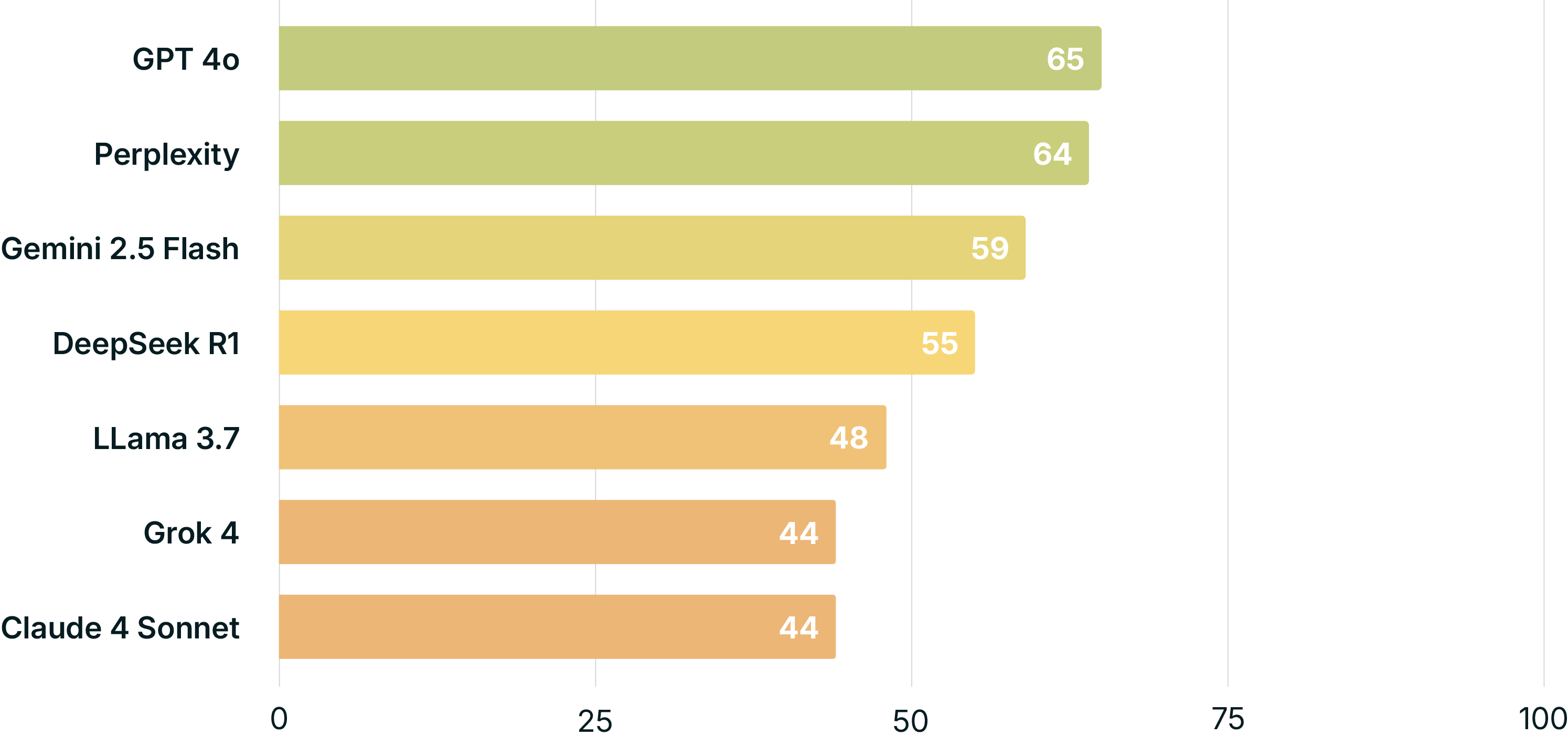
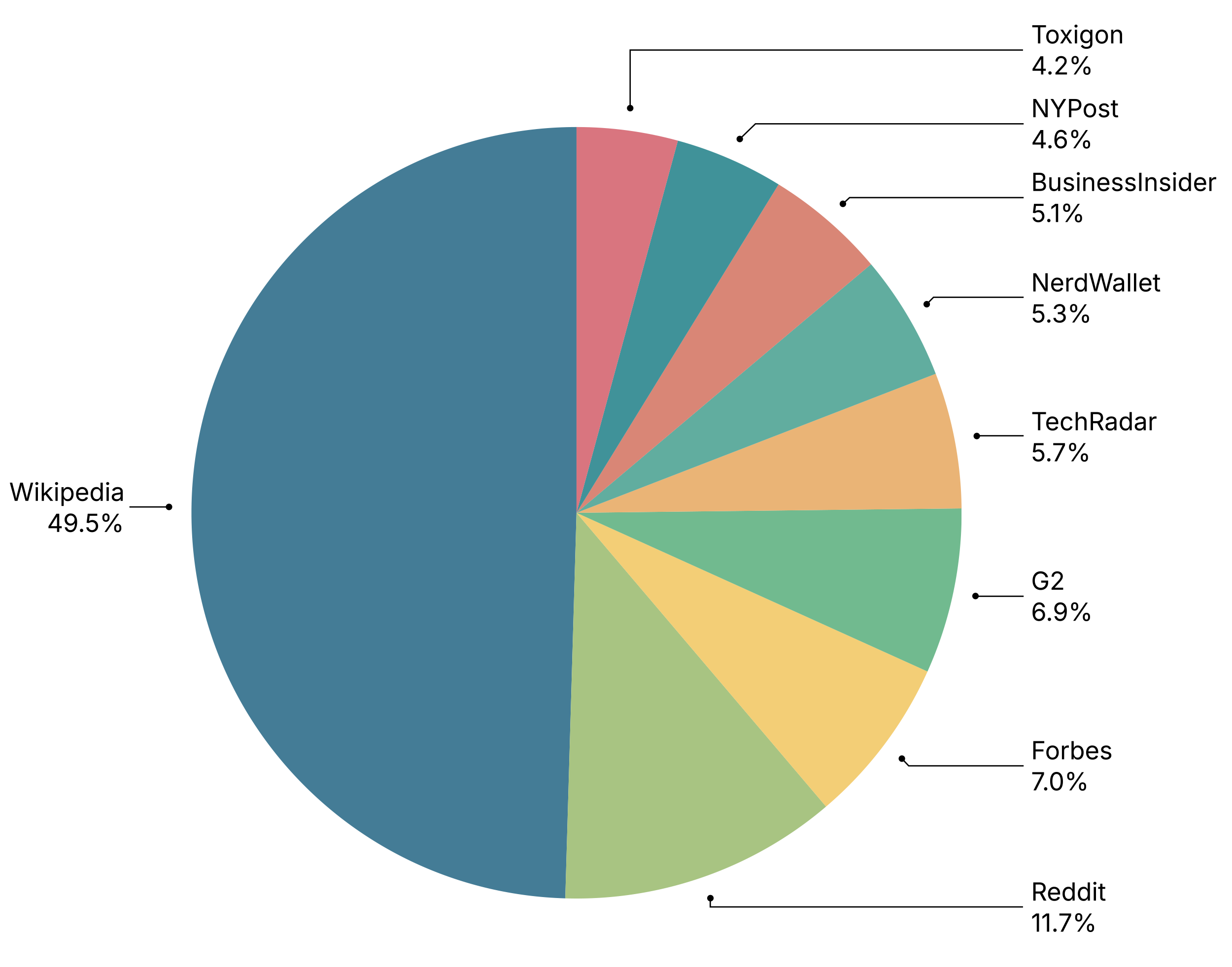
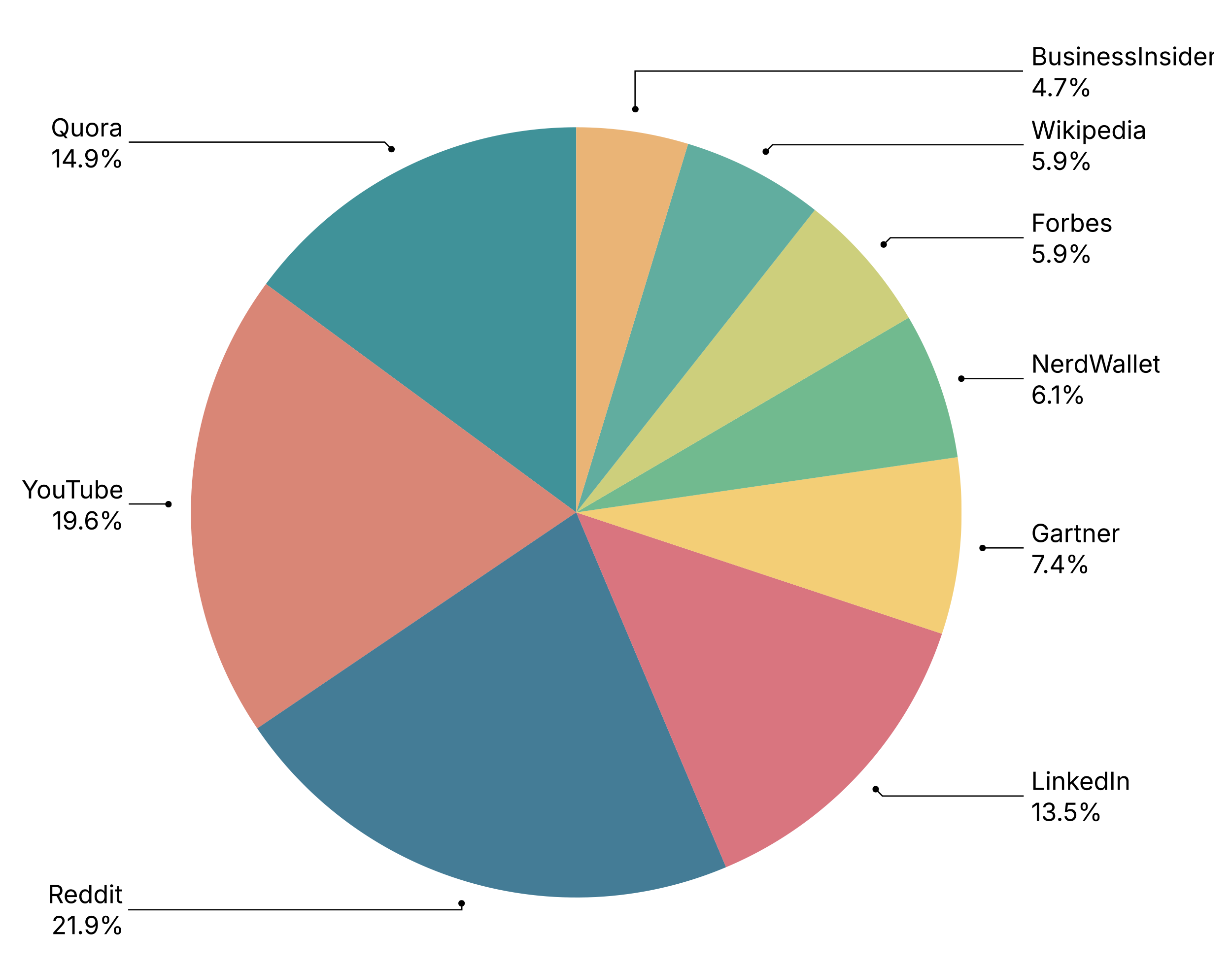
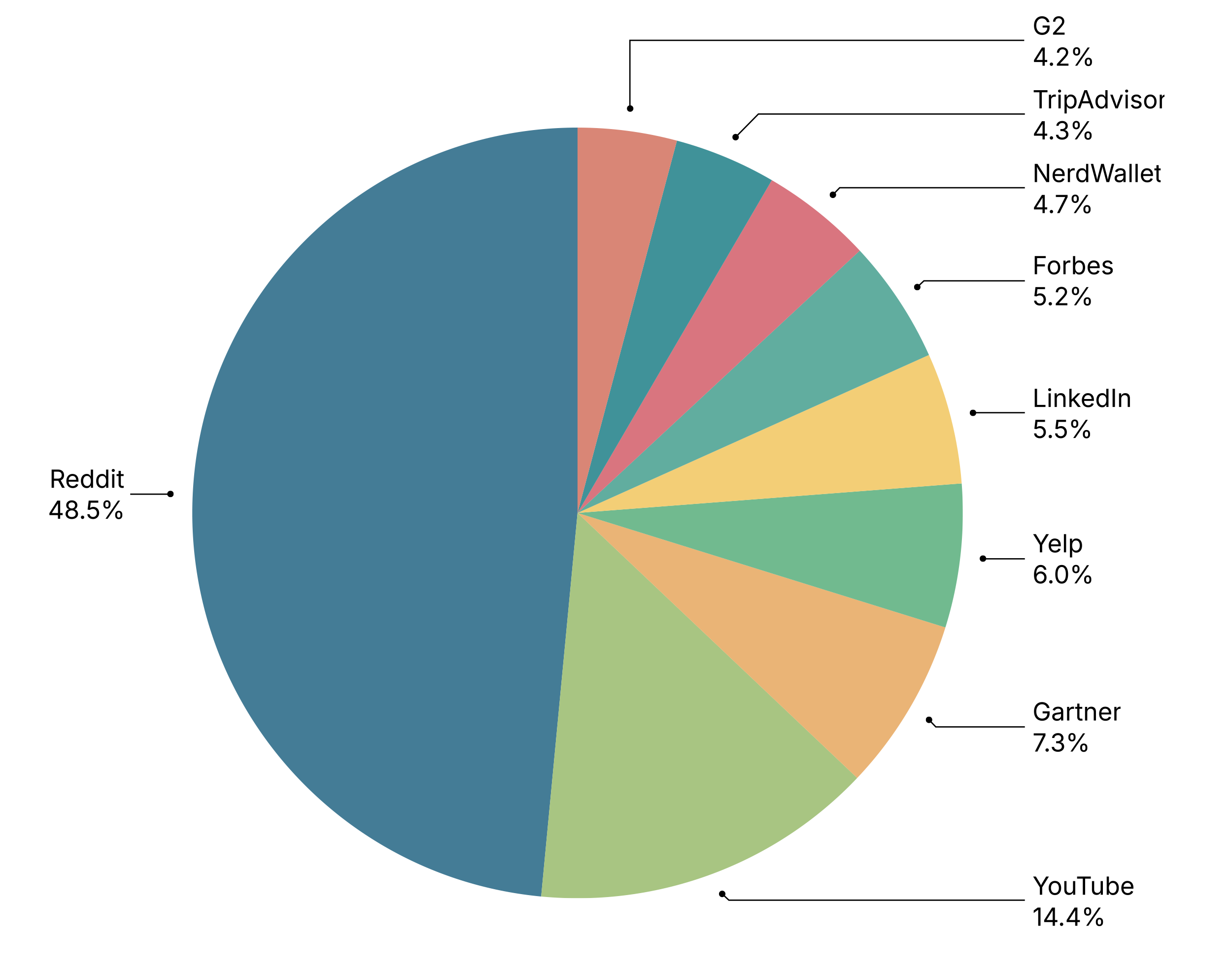
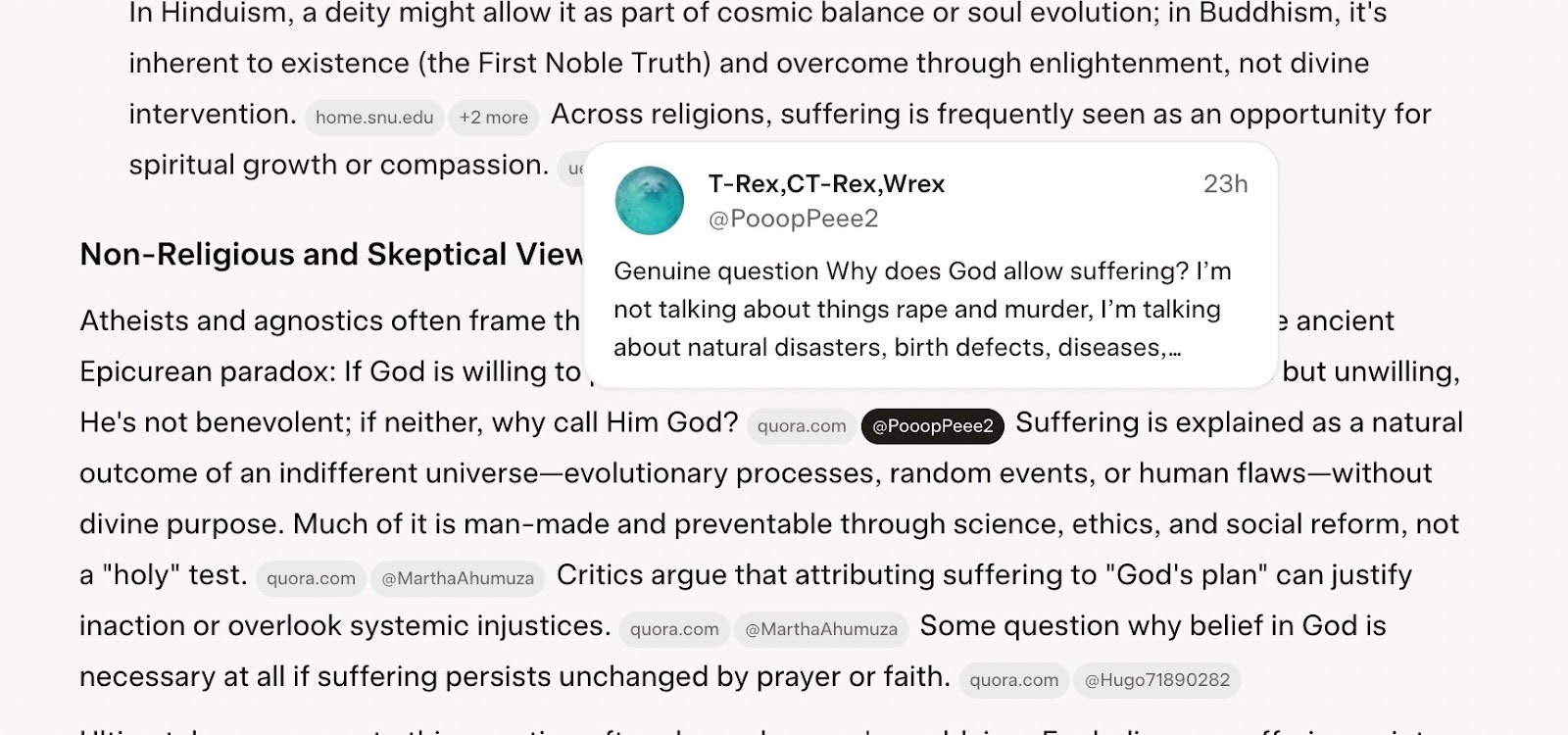
It is imperative that everyone, and especially Christians, understand how LLM technology works and what it is and isn’t capable of doing. The technology works by training on massive amounts of text where it finds patterns of words that often appear in proximity to each other. Then it makes statistical predictions about what other words should appear next to each other.
However, there is more human involvement in LLM technology than you think. Programming, weighting, and alignment are all needed to create the most helpful responses. We are not getting purely objective, dispassionate, or omniscient AI answers to our prompts. We are getting a consensus view that has been shaped by the various quirks, weights, values, and voice of that respective AI platform. Furthermore, different users entering identical prompts will receive different answers depending on whether the person has chat history A versus chat history B.
Don’t treat LLMs the same way as a Google search. Give them a few sentences of context when you are drafting prompts. Every LLM platform is fully capable of a perfect score in the AI Christian Benchmark given the proper inputs. You get that type of response by giving additional context in your prompt. “What is the gospel? Please give me responses consistent with the Nicene Creed…etc.”
At the end of the day it is also good for us to acknowledge human weakness and our propensity towards idols. Consider the words of the prophet Isaiah:
The carpenter stretches a line; he marks it out with a pencil. He shapes it with planes and marks it with a compass. He shapes it into the figure of a man, with the beauty of a man, to dwell in a house. He cuts down cedars, or he chooses a cypress tree or an oak and lets it grow strong among the trees of the forest. He plants a cedar and the rain nourishes it. Then it becomes fuel for a man. He takes a part of it and warms himself; he kindles a fire and bakes bread. Also he makes a god and worships it; he makes it an idol and falls down before it. Half of it he burns in the fire. Over the half he eats meat; he roasts it and is satisfied. Also he warms himself and says, “Aha, I am warm, I have seen the fire!” And the rest of it he makes into a god, his idol, and falls down to it and worships it. He prays to it and says, “Deliver me, for you are my god!” (44:13-17, ESV)